
2026年07月29日(水)
ネットベンチャーニュース
総務省とNICT、多分野翻訳データの集積を図る「翻訳バンク」を設置




- TOP
- >
- 総務省とNICT、多分野翻訳データの集積を図る「翻訳バンク」を設置
新着30件
2017年9月11日 22:30
自動翻訳システムの高度化を目指し運用開始
総務省と国立研究開発法人情報通信研究機構(NICT)は8日、自動翻訳システムのさまざまな分野への対応、さらなる高精度化を目的として、オール・ジャパン体制で多様な翻訳データを集積する「翻訳バンク」の運用を開始すると発表した。総務省とNICTでは、世界の“言葉の壁”をなくすことを目指し、グローバルコミュニケーション計画を推進、その取り組みの一環として、NICTでは、31カ国語に対応する独自の音声翻訳アプリ「VoiceTra」、テキスト自動翻訳システムの「TexTra」について研究・開発・社会実装を進める活動を行っている。
これまで翻訳結果の改善、高精度化に関しては、必要な翻訳データの収集・蓄積を図るとともに、今年6月からは、脳の神経回路を模した学習の仕組みで、従来技術よりも高い精度が実現可能になるとされる自動翻訳技術のニューラル機械翻訳技術の導入を進めるなどしてきた。しかし実現した翻訳技術も、活用分野によっては翻訳データが不足し、十分に力を発揮できないなど、課題も残されている。
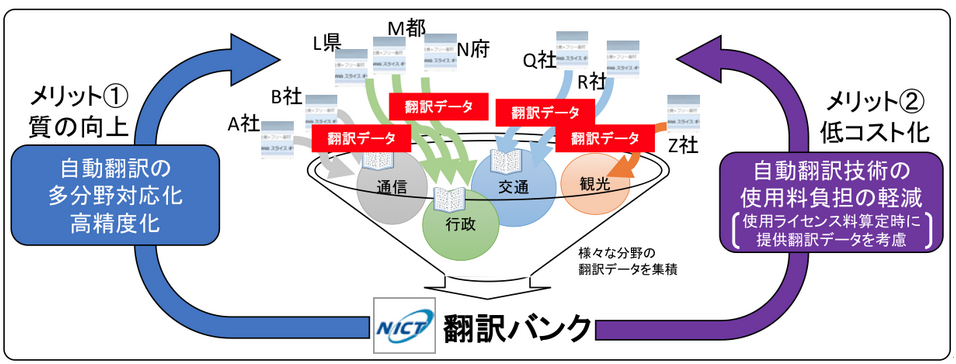
データの質と量を確保、多分野対応で国際競争力もアップ!
今後の自動翻訳技術における性能向上のためには、NICTが研究開発で取り組んでいる翻訳アルゴリズムの改良とともに、活用する翻訳データの質と量を十分に確保することがきわめて重要になる。そこで、新設・運用開始となったのが「翻訳バンク」だ。「翻訳バンク」では、より多様な分野の翻訳データを収集し、開発・改良中の自動翻訳技術に活用することで、対応可能な分野を拡張するとともに、さらなる高精度化を実現させていく。当面の目標として、100万文×100社、1億文の翻訳データ集積を目指すという。
運用にあたっては、データ提供側のメリットを明確化するため、実現したNICTの自動翻訳技術使用ライセンス料算定時に、提供が見込まれる翻訳データを勘案し、負担を軽減する仕組みも導入する。これにより「翻訳バンク」をめぐって双方にメリットがもたらされる好循環モデルを構築、低コストで効率よく、みなで技術を育てながら、高性能な自動翻訳技術を広く活用していく理想的なサイクルを生み出したいとしている。
総務省とNICTでは、今後もこうした取り組みを推進することを通じ、日本を『世界で最も多言語コミュニケーションが容易な国』にすることで、国内経済および社会の活性化、国際競争力の強化につなげていきたいとした。
(画像はプレスリリースより)
総務省/国立研究開発法人情報通信研究機構 プレスリリース
https://www.nict.go.jp/press/2017/09/08-1.html

-->
Facebook
記事検索
アクセスランキング トップ10
お問い合わせ